说明
该文档为学习python过程中觉得非常重要的内容(利于理解某些实现原理),也就是作为一名pythoner,必须知道的内容,但是好记性不如烂笔头,还是记下来,定时复习还是比较好的。
持续更新
重点
Python模块搜索机制
- 程序当前目录
- PYTHONPATH(环境变量)目录
- 标准库目录
CPython,PyPy,Jython
- CPython即底层用c/c++语言实现的Python,也是我们通常所用的python解释器
- PyPy是使用Python实现的python解释器,速度比CPython快
- Jython可以让python code跑在JVM上,并可以调用java code的解释器
一个项目标准文件层次结构

import导入模块顺序
- 标准库
- 第三方库
- 本地库
命名
- 类命名采用驼峰命名法
- 异常定义使用Error前缀
- 函数命名使用小写,并用下划线连接每个word
- 模块命名使用小写,word直接连接(较多)或者用下划线
库API
- 公共API:库暴露给用户使用的API
- 私有API:为实现功能,库内部使用的API,函数名前面有下划线
库更新时应该注意的问题
- 废弃的接口不要立即删除
- 可以在新版本中使用
warnings对使用废弃API的程序员显示警告信息
pip安装包
- 如果在linux系统,可以使用
pip install --user 包名来将包安装在home目录以避免在系统层面安装而造成操作系统目录的污染
for循环
- 当使用for循环的时候,for语句就会自动的通过
__iter__()方法来获得迭代器对象,并且通过__next__()方法来获取下一个元素
可迭代与迭代器
- 如果一个对象具有
__iter__()方法,那么它便是一个可迭代对象(iterable) - 如果一个可迭代对象具有
next()(python 2)或者__next__()(python 3)方法,并且函数返回是return而不是yield,那么它就是一个迭代器(iterator)
生成器
- 生成器是特殊的迭代器,关键字
yield就表示该方法返回一个生成器对象,其__next__()方法就是执行到下一次yield,其__iter__()方法就是返回自身,可以用for循环执行生成器中的代码。当循环结束,或不满足if/else条件时,导致函数运行但不命中yield关键字,此时生成器触发StopIteration异常。 - 调用生成器时
__next__()方法时,实际上是将函数状态挂起,也就是保存了栈帧的状态
|
|
|
|
yield表达式
|
|
|
|
可以通过send()方法向生成器发送数据,(yield i)表达式的值就是send(value)中的value,而默认情况,(yield i)表达式的值为None
列表解析与生成器表达式
[]返回列表()返回生成器
迭代器与生成器
- 两者都比list节省内存,也就是运行的时候才生成数据,而不是像list一次性存储全部数据
- 生成器的编写比自定义一个迭代器简单很多,使用
yield关键字或者()表达式就可以返回一个生成器,而不用自己写__iter__()与__next__()方法,并且生成器可以做更多的事情 - 生成器在进行迭代的时候只是暂停,并不是结束,而
finally语句中的内容是在结束的时候才执行的 list()tuple()max()min()等函数以及in,not in操作符都支持迭代器或者生成器作为参数,但是要注意如果迭代器或者生成器是无限的,那么很明显会一直循环,所以使用前要搞清楚迭代器或生成器是否是有限的- 对字典进行
for操作,默认是获取的key的迭代器,并且注意普通字典是无序的,要想获取value的迭代器或者是key/value的迭代器,就调用字典的values()和items()方法
迭代器与内置函数
map(f, iterA, iterB, ...)returns an iterator over the sequencef(iterA[0], iterB[0]), f(iterA[1], iterB[1]), f(iterA[2], iterB[2]), ....filter(predicate, iter)returns an iterator over all the sequence elements that meet a certain conditionenumerate(iter)counts off the elements in the iterable, returning 2-tuples containing the count and each elementsorted(iterable, key=None, reverse=False)collects all the elements of the iterable into a list, sorts the list, and returns the sorted resultany(iter)andall(iter)built-ins look at the truth values of an iterable’s contents.any()returnsTrueif any element in the iterable is a true value, andall()returnsTrueif all of the elements are true valueszip(iterA, iterB, ...)takes one element from each iterable and returns them in a tuple.It doesn’t construct an in-memory list and exhaust all the input iterators before returning; instead tuples are constructed and returned only if they’re requested. (The technical term for this behaviour is lazy evaluation.)functools.reduce(func, iter, [initial_value])cumulatively performs an operation on all the iterable’s elements and, therefore, can’t be applied to infinite iterables.funcmust be a function that takes two elements and returns a single value.functools.reduce()takes the first two elementsAandBreturned by the iterator and calculatesfunc(A, B). It then requests the third element,C, calculatesfunc(func(A, B), C), combines this result with the fourth element returned, and continues until the iterable is exhausted. If the iterable returns no values at all, aTypeErrorexception is raised. If the initial value is supplied, it’s used as a starting point andfunc(initial_value, A)is the first calculation.参考 python的reduce()函数reduce常与operator模块中的函数搭配使用
列表与元组
- 列表与远足最大的区别就是前者可变,后者不可变,所以元组较安全
绑定与非绑定方法
|
|
log
- 级别从低到高为
DEBUGINFOWARNINGERRORCRITICAL - 默认级别为
WARNING,只有WARNING和之上的级别的log控制台才会被输出 - python logging模块使用教程 Python logging模块详解
sorted
- 可处理简单列表排序和针对对象中某一属性进行排序,并且与
sort()不同,前者不改变原列表,后者直接修改原列表 - 使用方法参考Sorting HOW TO
ipaddress
- 该模块能提供一些方法对ipv4和ipv6进行识别和处理
类
当一个类定义被执行,发生了这些事:
- 一个合适的元类被确定
- 类命名空间被准备好
- 类主体被执行
- 类对象被创建
类是元类的实例,在python中,一切都是对象,类也是对象
特殊方法
__new__()是特殊的不用声明的静态方法__mro__()返回类所有的父类
文件操作
os.listdir()获取的只是指定路径下所有文件名组成的字符串列表,os.scandir()这可以返回一个生成器,每个元素是DirEntry对象,保留了文件相关的信息os.remove()只能删除文件,os.rmdir()只能删除空目录,shutil.rmtree()可以递归删除目录
subprocess替代
keyring
- 该模块能够将密码保存在系统keyring服务中
random 与urandom
- random是标准库中的一个模块,产生的随机数不安全
- urandom()是os模块中的方法,使用基于系统的随机数生成器,是安全的
python2与3的编码问题
Python2有两种表示字符序列的类型,分别叫做
str和Unicode,str实例包含原始的8位值;而Unicode的实例,则包含Unicode字符。str格式本质含义是“某种编码格式”,绝大多数情况下,被引号框起来的字符串,就是str,这时的字符串编码类型,其实就是你Python文件的编码类型,比如在Windows里,默认用的是GBK编码。Unicode格式的含义就是“用unicode编码的字符串”。Python在进入2.0版后正式定义了了Unicode字符串这个奇怪的特性,目的就是为了处理太多种语言编码的文本。从那时开始,Python语言中的字符串类型就分为两种:一种是传统的Python字符串(各种花样编码),另一种则是新出现的Unicode
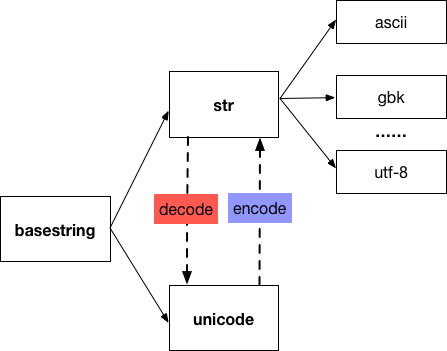
Python3也有两种表示字符序列的类型:
bytes和str。前者的实例包含原始的8位值,后者的实例包含Unicode字符,可以说python3的str,就是python2的Unicodestr格式的定义变更为”Unicode类型的字符串“,也就是说在默认情况下,被引号框起来的字符串,是使用Unicode编码的。- 而“不是Unicode的某种编码格式”,比如UTF-8、GBK,这些编码方式被定义为了
bytes,这里的bytes和py2中的str有很多相似的地方
我们需要编写两个辅助(helper)函数,以便在这两种情况之间转换,使得转换后的输入数据能够符合开发者的预期
123456789101112131415161718192021222324252627282930313233#在Python3中,我们需要编写接受str或bytes,并总是返回str的方法:def to_str(bytes_or_str):if isinstance(bytes_or_str, bytes):value = bytes_or_str.decode('utf-8')else:value = bytes_or_strreturn value # Instance of str#另外,还需要编写接受str或bytes,并总是返回bytes的方法:def to_bytes(bytes_or_str):if isinstance(bytes_or_str, str):value = bytes_or_str.encode('utf-8)else:value = bytes_or_strreturn value # Instance of bytes#在Python2中,需要编写接受str或unicode,并总是返回unicode的方法:#python2def to_unicode(unicode_or_str):if isinstance(unicode_or_str, str):value = unicode_or_str.decode('utf-8')else:value = unicode_or_strreturn value # Instance of unicode#另外,还需要编写接受str或unicode,并总是返回str的方法:#Python2def to_str(unicode_or_str):if isinstance(unicode_or_str, unicode):value = unicode_or_str.encode('utf-8')else:value = unicode_or_strreutrn vlaue # Instance of str
contextlib
- 使用
contextlib标准库可以快速构造上下文管理器 - 使用
contextlib库中的contextmanager装饰器装饰一个返回生成器的函数,就构造了一个上下文管理器,其中yield前面的内容是with表达式执行之前的操作,yield之后的内容是with表达式执行之后的操作,yield如果有返回的内容,则会返回给with表达式中as之后的变量
打包python包到pypi
装饰器
|
|
上述就是一个最简单的装饰器的实现,实际上,装饰器就是实现了下面的操作:
|
|
注册装饰器的实现:
|
|
上述装饰器没有使用被装饰函数的参数,返回的还是原来的函数,只是在返回之前做了一些事情
而大多数装饰器都会用到被装饰函数的参数,这时候就不能返回函数本身了,因为最后返回函数本身,就没有渠道获取被装饰函数的参数,所以这时候就需要返回一个对被装饰函数进行包装的函数,例如:
|
|
get_food被装饰后,实际上我们在调用get_food时,调用的是wrapper函数,也就是说get_food被包装了,所以wrapper可以获取到输入的参数,并对参数进行一些操作,并且注意上述代码要传入一个名为username的关键字参数,例如:
|
|
为此,我们需要一个更加智能的装饰器,它能够查看被装饰函数的参数,并从中提取需要的参数,inspect模块能实现这样的需求
并且由于实际上我们调用的是包装函数wrapper,那么像__name__等返回的就是wrapper函数的信息,而不是get_food函数的信息,为此,functools提供wraps装饰器用来将被装饰函数一些特有属性赋值给包装函数,这样我们使用wrapper函数时,就像真的在使用原get_food函数一样
|
|

